Anonymisation (ANM)¶
The anonymization service provides the means to anonymize data. In particular it support Macro Anonymization - adding noise to queries - as well as Micro Anonymization which generalizes values for the release of personal records in data sets. The service provides REST API’s that allow a user to configure the service, upload data, anonymize the data and finally download the anonymized data.
Functionality¶
The anonymization service provided the necessary functionality to anonymize (micro, macro) a data set. It allows a privacy expert to configure and then perform the anonymization. The Anonymization flow is very simple:
- Upload configuration (which contains necessary anonymization parameters as well as data format and data types)
- Upload Data
- Perform anonymization
- Download anonymized data (for micro only)
All the functionalities are invoked via RESTful calls. Examples are provided in the deployment guide.
Anonymisation Interface (ANI)¶
Related to Macro anonymization, the statistical data API of ANM is also integrated with the Service Ledger blockchain to provide a greater level of control for privacy protection of data sets. This integration is realised via the Anonymisation Interface (ANI), whose high-level behaviour is here detailed
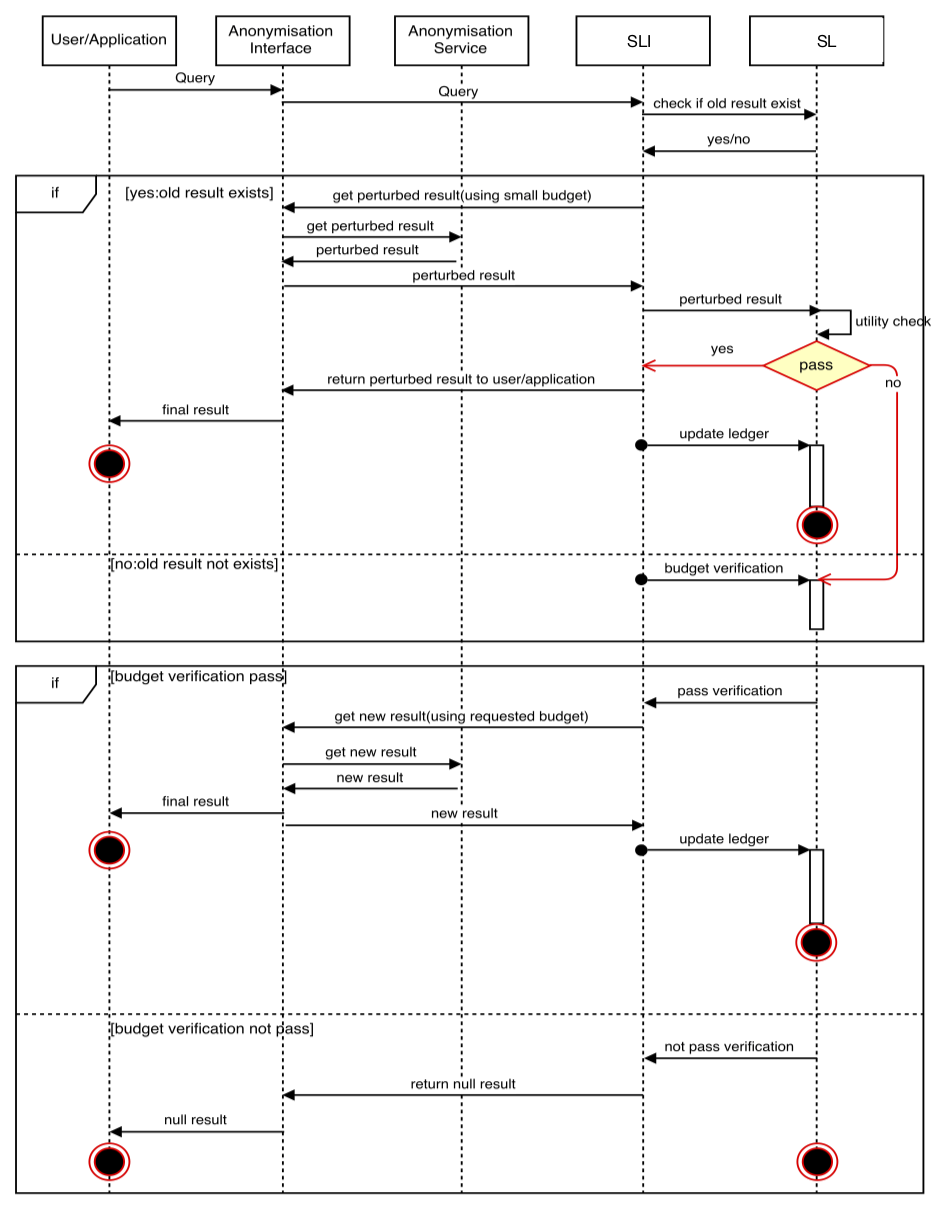
This blockchain-based anonymization approach relies on two phases:
- Setup, to put in place privacy and data utility requirements, and
- Runtime, to dynamically control privacy budgets and tune the data sharing process.
Blockchain smart contracts are used to store, evaluate and keep track of historical queries and privacy budget. These functionalities empower untrusted privacy services of a Cloud federation.
Setup¶
At the Setup phase, data owners provide their privacy and data utility requirements which are then stored in the smart contract. The privacy requirement is represented by the privacy budget, which represents the maximum amount of budget allowed on sharing data. According to data owner preferences, the budget can be associated to one or many datasets, or even to single columns of a single dataset. Data utility requirement is represented by a numerical variable, representing the maximum amount of noise allowed on the actual query result, thus to maintain adequate data utility.
Runtime¶
At the Runtime phase, data queries are managed returning anonymized results, when allowed by the privacy budget and requirements. Indeed, our approach M consists of an unbounded sequence of mechanisms M_1,M_2,… , , where M_i operates when the i-th query is received. Logically, it can be decomposed into three main test activities:
- Query matching: it aims at determining whether a newly received query has been executed before. Smart contract checks the sharing history stored on the blockchain;
- Utility-based approximation: it aims at checking whether a previous released result can approximate the result to return for the current query;
- Budget verification: this test is triggered if there has been no same query executed (i.e., the query matching test failed), or the query result cannot be approximated (i.e., the approximation test failed). Thus, a new result has to be computed, as long as the remaining privacy budget is enough.